7. Konwolucyjne sieci neuronowe
Konwolucyjne sieci neuronowe (ang. Convolutional Neural Networks, CNN) to klasa sieci neuronowych, które są szczególnie skuteczne w zadaniach związanych z analizą obrazów, takich jak klasyfikacja, detekcja obiektów czy segmentacja. Nadają się również do analizy serii czasowych (np. sygnałów dźwiękowych, EKG itd.) poprzez zastosowanie konwolucji 1D.
W odróżnieniu od tradycyjnych sieci gęstych, które łączą każdy neuron z każdym innym neuronem w kolejnej warstwie, sieci konwolucyjne wykorzystują operację konwolucji, która pozwala na wykrywanie lokalnych wzorców w danych wejściowych.
Note
Opis sieci konwolucyjnych można znaleźć m.in. tu: https://d2l.ai/chapter_convolutional-neural-networks/index.html
7.1. Sieci konwolucyjne 1D
Jednowymiarowe sieci konwolucyjne (ang. 1D Convolutional Neural Networks) są stosowane głównie do analizy danych sekwencyjnych (np. wyników pomiarów EKG). W sieciach tego rodzaju operacja konwolucji jest wykonywana wzdłuż jednej osi (np. czasu), co pozwala na wykrywanie wzorców czasowych w danych.
Prześledźmy teraz na przykładzie, jak działa operacja konwolucji 1D. Załóżmy, że mamy ciąg danych wejściowych oraz filtr (jądro konwolucyjne), który chcemy zastosować do tego ciągu.
Załóżmy, że mamy ciąg danych wejściowych \(X\) o długości 5 oraz filtr \(W\) o długości 3:
Będziemy chcieli teraz znaleźć ciąg wyjściowy \(Y\) poprzez zastosowanie operacji konwolucji, która polega na przesuwaniu filtra wzdłuż ciągu wejściowego i obliczaniu sumy ważonej elementów wejściowych i odpowiadających im wag filtra. Dla każdego przesunięcia filtra obliczamy wartość wyjściową jako:
Dla \(i = 3\) odczytujmy wartość \(x_5\), tak więc jest to ostatni indeks, który możemy tu zastosować. Ostatecznie ciąg wyjściowy \(Y\) będzie miał długość 3 i będzie wyglądał następująco:
Podstawmy dla przykładu konkretne liczby.
Załóżmy, że mamy ciąg wejściowy:
oraz filtr:
Wyliczamy po kolei wartości wyjściowe:
\(y_1 = 1 \cdot 1 + 0 \cdot 2 + (-2) \cdot 3 = 1 + 0 - 6 = -5\)
\(y_2 = 1 \cdot 2 + 0 \cdot 3 + (-2) \cdot 4 = 2 + 0 - 8 = -6\)
\(y_3 = 1 \cdot 3 + 0 \cdot 4 + (-2) \cdot 5 = 3 + 0 - 10 = -7\)
Ostatecznie ciąg wyjściowy \(Y\) będzie wyglądał następująco:
7.1.1. Dodatkowe techniki w sieciach konwolucyjnych
W powyższym przykładzie filtr został przesunięty o jeden element (stride = 1), nie zastosowano żadnego paddingu (czyli nie dodano żadnych dodatkowych wartości do ciągu wejściowego), zastosowano dilation = 1 (czyli nie wprowadzono żadnych przerw między elementami filtra) oraz nie zastosowano żadnej operacji pooling. W praktyce jednak często stosuje się te techniki, aby kontrolować rozmiar wyjścia, zwiększyć zasięg wykrywania wzorców lub zmniejszyć wymiarowość danych.
Oto krótkie omówienie tych technik.
7.1.1.1. Padding
Padding polega na dodaniu dodatkowych wartości (np. zer) do ciągu wejściowego, co pozwala na kontrolowanie rozmiaru wyjścia oraz umożliwia wykrywanie wzorców na krawędziach danych wejściowych. Na przykład, jeśli zastosujemy padding o szerokości 1 (dodając jedno zero na początku i jedno zero na końcu ciągu wejściowego), to nasz ciąg wejściowy przyjmie następującą postać:
Dzięki temu filtr będzie mógł być zastosowany również do elementów na krawędziach ciągu wejściowego, a ciąg wyjściowy będzie miał długość 5 (zamiast 3):
7.1.1.2. Stride
Stride określa, o ile elementów przesuwamy filtr wzdłuż ciągu wejściowego. W powyższym przykładzie zastosowano domyślny stride równy 1, co oznacza, że filtr przesuwa się o jeden element na raz. Zwiększenie wartości stride powoduje zmniejszenie rozmiaru wyjścia, ponieważ filtr przeskakuje pewne elementy wejściowe.
Gdyby zastosowano stride równy 2, to filtr przesuwałby się o dwa elementy na raz, a ciąg wyjściowy miałby długość 2:
7.1.1.3. Dilation
Dilation polega na wprowadzeniu przerw między elementami filtra, co pozwala na wykrywanie wzorców o większym zasięgu bez konieczności zwiększania rozmiaru filtra. Na przykład, jeśli zastosujemy dilation równy 2, to filtr będzie wyglądał następująco:
Dla naszego ciągu wejściowego 7.1 oraz wartości filtra 7.2 w przypadku z dilation równym 2, ciąg wyjściowy (jednoelementowy) będzie wyglądał następująco:
7.1.1.4. Pooling
Pooling to operacja, która służy do zmniejszenia wymiarowości danych wyjściowych z warstwy konwolucyjnej poprzez agregację wartości w określonym obszarze (np. maksymalna wartość, średnia wartość). Na przykład, jeśli zastosujemy operację max pooling z rozmiarem okna 3 i stride równym 2 do ciągu wyjściowego \(Y\) z naszego pierwszego przykładu, to otrzymamy:
Jak widać, w przypadku poolingu nie uwzględnia się wartości macierzy jądra \(W\). Operacja pooling nie posiada żadnych parametrów, które podlegają uczeniu.
7.1.2. Obliczanie gradientów
Prześledźmy teraz w jaki sposób obliczane są gradienty względem wejścia (\(dX\)) oraz względem parametrów (\(dW\)) w przypadku operacji konwolucji 1D.
Niech \(dY\) będzie otrzymanym gradientem straty względem ciągu wyjściowego \(Y\). Oznaczmy też odwrócony filtr jako \(W_{\text{flipped}}\):
Gradient względem ciągu wejściowego \(X\) można obliczyć jako konwolucję gradientu \(dY\) z filtrem \(W\) odwróconym:
Gradient względem filtra \(W\) można obliczyć jako konwolucję ciągu wejściowego \(X\) z gradientem \(dY\):
7.1.2.1. Przykład liczbowy
Przeliczmy teraz na konkretnych wartościach gradienty względem wejścia i parametrów dla naszego przykładu z:
- ciągiem wejściowym \(X\) (uzupełnionym paddingiem do postaci ze wzoru 7.4),
- filtrem \(W\) (wzór 7.2),
- wyjściem \(Y\) (wzór 7.5),
- oraz gradientem \(dY\) równym:
Dla powyższych wartości możemy obliczyć gradient względem wejścia \(dX\) (wg wzoru 7.6):
\(dx_1 = w_3 \cdot 0 [padding] + w_2 \cdot dy_1 + w_1 \cdot dy_2 = 0 + 0 + 1 \cdot (-4) = -4\)
\(dx_2 = w_3 \cdot dy_1 + w_2 \cdot dy_2 + w_1 \cdot dy_3 = (-2) \cdot (-2) + 0 \cdot (-4) + 1 \cdot (-6) = 4 + 0 - 6 = -2\)
\(dx_3 = w_3 \cdot dy_2 + w_2 \cdot dy_3 + w_1 \cdot dy_4 = (-2) \cdot (-4) + 0 \cdot (-6) + 1 \cdot (-8) = 8 + 0 - 8 = 0\)
\(dx_4 = w_3 \cdot dy_3 + w_2 \cdot dy_4 + w_1 \cdot dy_5 = (-2) \cdot (-6) + 0 \cdot (-8) + 1 \cdot (-10) = 12 + 0 - 10 = 2\)
\(dx_5 = w_3 \cdot dy_4 + w_2 \cdot dy_5 + w_1 \cdot 0 [padding] = (-2) \cdot (-8) + 0 \cdot (-10) + 1 \cdot 0 = 16 + 0 + 0 = 16\)
Tak więc:
Natomiast gradient względem filtra \(W\) można obliczyć w sposób następujący (wg wzoru 7.7):
\(dw_1 = x_1 \cdot dy_1 + x_2 \cdot dy_2 + x_3 \cdot dy_3 + x_4 \cdot dy_4 + x_5 \cdot dy_5 =\) \(0 \cdot (-2) + 1 \cdot (-4) + 2 \cdot (-6) + 3 \cdot (-8) + 4 \cdot (-10) =\) \(0 - 4 - 12 - 24 - 40 = -80\)
\(dw_2 = x_2 \cdot dy_1 + x_3 \cdot dy_2 + x_4 \cdot dy_3 + x_5 \cdot dy_4 + x_6 \cdot dy_5 =\) \(1 \cdot (-2) + 2 \cdot (-4) + 3 \cdot (-6) + 4 \cdot (-8) + 5 \cdot (-10) =\) \(-2 - 8 - 18 - 32 - 50 = -110\)
\(dw_3 = x_3 \cdot dy_1 + x_4 \cdot dy_2 + x_5 \cdot dy_3 + x_6 \cdot dy_4 + x_7 \cdot dy_5 =\) \(2 \cdot (-2) + 3 \cdot (-4) + 4 \cdot (-6) + 5 \cdot (-8) + 0 \cdot (-10) =\) \(-4 - 12 - 24 - 40 + 0 = -80\)
A więc ostatecznie:
7.1.3. Implementacja w bibliotece NeuralNetworks
Poniżej przedstawiono przykładową implementację operacji konwolucji 1D oraz obliczania gradientów względem wejścia i parametrów w bibliotece NeuralNetworks. Implementacja w tym kształcie (wersja "naiwna") znajduje się w klasie OperationsArray.
public virtual float[,,] Convolve1DOutput(float[,,] input, float[,,] weights, int padding, int stride = 1, int dilatation = 0)
{
int batchSize = input.GetLength(0);
int inputChannels = input.GetLength(1);
int inputLength = input.GetLength(2);
int outputChannels = weights.GetLength(1);
int kernelLength = weights.GetLength(2);
Debug.Assert(weights.GetLength(0) == inputChannels);
int effectiveInputLength = inputLength + 2 * padding;
int effectiveKernelLength = dilatation * (kernelLength - 1) + kernelLength;
int outputLength = (effectiveInputLength - effectiveKernelLength) / stride + 1;
float[,,] output = new float[batchSize, outputChannels, outputLength];
for (int b = 0; b < batchSize; b++)
{
for (int oc = 0; oc < outputChannels; oc++)
{
for (int ol = 0; ol < outputLength; ol++)
{
float sum = 0.0f;
for (int ic = 0; ic < inputChannels; ic++)
{
for (int kl = 0; kl < kernelLength; kl++)
{
int il = ol * stride + kl * dilatation - padding;
if (il >= 0 && il < inputLength)
{
sum += input[b, ic, il] * weights[ic, oc, kl];
}
}
}
output[b, oc, ol] = sum;
}
}
}
return output;
}
public virtual float[,,] Convolve1DInputGradient(float[,,] input, float[,,] weights, float[,,] outputGradient, int padding, int stride = 1, int dilatation = 0)
{
int inputChannels = input.GetLength(1);
int inputLength = input.GetLength(2);
int batchSize = outputGradient.GetLength(0);
int outputChannels = outputGradient.GetLength(1);
int outputLength = outputGradient.GetLength(2);
int kernelLength = weights.GetLength(2);
Debug.Assert(weights.GetLength(0) == inputChannels);
float[,,] inputGradient = new float[batchSize, inputChannels, inputLength];
for (int b = 0; b < batchSize; b++)
{
for (int ic = 0; ic < inputChannels; ic++)
{
for (int il = 0; il < inputLength; il++)
{
float sum = 0.0f;
for (int oc = 0; oc < outputChannels; oc++)
{
for (int kl = 0; kl < kernelLength; kl++)
{
int ol = (il + padding - kl * dilatation) / stride;
if (ol >= 0 && ol < outputLength && (il + padding - kl * (dilatation + 1)) % stride == 0)
{
sum += outputGradient[b, oc, ol] * weights[ic, oc, kl];
}
}
}
inputGradient[b, ic, il] += sum;
}
}
}
return inputGradient;
}
public virtual float[,,] Convolve1DParamGradient(float[,,] input, float[,,] outputGradient, int padding, int stride, int dilatation)
{
int inputChannels = input.GetLength(1);
int inputLength = input.GetLength(2);
int batchSize = outputGradient.GetLength(0);
int outputChannels = outputGradient.GetLength(1);
int outputLength = outputGradient.GetLength(2);
int kernelLength = (inputLength + 2 * padding - (outputLength - 1) * stride) / (dilatation + 1);
float[,,] paramGradient = new float[inputChannels, outputChannels, kernelLength];
for (int b = 0; b < batchSize; b++)
{
for (int ic = 0; ic < inputChannels; ic++)
{
for (int oc = 0; oc < outputChannels; oc++)
{
for (int kl = 0; kl < kernelLength; kl++)
{
float sum = 0.0f;
for (int ol = 0; ol < outputLength; ol++)
{
int il = ol * stride + kl * dilatation - padding;
if (il >= 0 && il < inputLength)
{
sum += outputGradient[b, oc, ol] * input[b, ic, il];
}
}
paramGradient[ic, oc, kl] += sum;
}
}
}
}
return paramGradient;
}
Listing 7.1. Podstawowa implementacja metod konwolucyjnych 1D w bibliotece NeuralNetworks
W powyższym kodzie zostały użyte następujące zmienne:
input- odpowiednik \(X\) z uwzględnieniem batch size i kanałów wejściowych (o wymiarach [batchSize, inputChannels, inputLength])weights- odpowiednik \(W\) z uwzględnieniem kanałów wejściowych i wyjściowych (o wymiarach [inputChannels, outputChannels, kernelLength])outputGradient- odpowiednik \(dY\) (o wymiarach [batchSize, outputChannels, outputLength])inputGradient- odpowiednik \(dX\) (o wymiarach [batchSize, inputChannels, inputLength])paramGradient- odpowiednik \(dW\) (o wymiarach [inputChannels, outputChannels, kernelLength])padding,stride,dilatation- parametry konwolucji
7.1.4. Przykład zastosowania: zbiór ECG200
Zbiór ECG200 to popularny zbiór danych zawierający sygnały EKG, który jest często wykorzystywany do testowania i porównywania różnych modeli sieci konwolucyjnych 1D. Zbiór ten zawiera 200 próbek sygnałów EKG, z których każda jest oznaczona jako należąca do jednej z dwóch klas (zdrowy lub chory). Każdy sygnał EKG składa się z 96 punktów pomiarowych, co czyni go dobrym kandydatem do analizy za pomocą sieci konwolucyjnych 1D.
W oryginalnym zbiorze dane są oznaczone dwiema etykietami: 1 (zdrowy) oraz -1 (chory). Jednak po przekodowaniu etykiet na (odpowiednio) 1 i 0, możliwe będzie użycie w warstwie wyjściowej funkcji aktywacji Sigmoid.
Celem jest zbudowanie modelu, który będzie w stanie poprawnie klasyfikować sygnały EKG na podstawie tych etykiet.
Sprawdźmy więc jak można zaimplementować prostą sieć konwolucyjną 1D do klasyfikacji sygnałów z tego zbioru danych, wykorzystując bibliotekę NeuralNetworks.
Note
Poniższy kod w pełnej wersji znajduje się na GitHub.
7.1.4.1. Architektura modelu
W celu klasyfikacji sygnałów EKG z zbioru ECG200 możemy zastosować następującą architekturę sieci konwolucyjnej 1D:
internal class Ecg200Model(SeededRandom? random)
: BaseModel<float[,,], float[,]>(new BinaryCrossEntropyLoss(), random)
{
protected override LayerListBuilder<float[,,], float[,]> CreateLayerListBuilder()
{
ParamInitializer initializer = new GlorotInitializer(Random);
Dropout3D dropout = new(0.76f, Random);
return
AddLayer(new Conv1DLayer(
kernels: 16,
kernelLength: 5,
stride: 1,
activationFunction: new ReLU3D(),
paramInitializer: initializer,
dropout: dropout
))
.AddLayer(new MaxPooling1DLayer(2))
.AddLayer(new Conv1DLayer(
kernels: 32,
kernelLength: 3,
stride: 1,
activationFunction: new ReLU3D(),
paramInitializer: initializer
))
.AddLayer(new GlobalAveragePooling1DLayer())
.AddLayer(new DenseLayer(1, new Linear(), initializer));
}
}
Listing 7.2. Przykładowa architektura sieci konwolucyjnej 1D do klasyfikacji sygnałów EKG z zbioru ECG200
Architektura ta składa się z następujących warstw:
- warstwa konwolucyjna 1D z 16 filtrami o długości 5, z funkcją aktywacji ReLU oraz dropoutem o współczynniku 0.76
- warstwa max pooling 1D z oknem o rozmiarze 2
- warstwa konwolucyjna 1D z 32 filtrami o długości 3, z funkcją aktywacji ReLU
- warstwa global average pooling 1D
- warstwa gęsta (Dense) z liniową funkcją aktywacji, która po późniejszym zastosowaniu funkcji Sigmoid zwraca prawdopodobieństwo przynależności sygnału EKG do klasy 1 (np. zdrowy)
Global average pooling jest to operacja, która oblicza średnią wartość dla każdego kanału wyjściowego z warstwy konwolucyjnej dla każdej próbki w batchu. Dzięki temu redukujemy wymiarowość danych do jednego wektora na próbkę o wymiarze równym liczbie kanałów wyjściowych z ostatniej warstwy konwolucyjnej. Innymi słowy, po wyjściu z ostatniej warstwy konwolucyjnej 1D, która zwraca dane o wymiarach [batchSize, outputChannels, outputLength], warstwa global average pooling 1D zwraca dane o wymiarach [batchSize, outputChannels], gdzie każda wartość jest średnią z odpowiedniego kanału wyjściowego dla danej próbki.
Jako funkcję straty dla naszego modelu wybrano funkcję Sigmoid Binary Cross Entropy, która jest odpowiednia do problemów klasyfikacji binarnej.
Funkcja straty Sigmoid Binary Cross Entropy w swoich obliczeniach wykorzystuje funkcję Sigmoid, która zwraca wartość z przedziału (0, 1), interpretowaną jako prawdopodobieństwo przynależności do klasy 1 (zdrowy). Wykres funkcji Sigmoid przedstawiono na rysunku 5.5.
Gdybyśmy zamiast liniowej funkcji aktywacji w warstwie gęstej zastosowali funkcję aktywacji Sigmoid, to na wyjściu otrzymalibyśmy bezpośrednio prawdopodobieństwo przynależności do klasy 1 (zamiast logitów). Funkcją straty byłaby wówczas funkcja Binary Cross Entropy, jednakże wymagałoby to obliczania - oprócz gradientu straty - również gradientu funkcji Sigmoid względem wyjścia warstwy gęstej, co byłoby mniej efektywne. Innymi słowy, łatwiej jest obliczyć przejście w przód i w tył dla układu: funkcja liniowa + Sigmoid Binary Cross Entropy, niż dla układu: funkcja Sigmoid + Binary Cross Entropy.
7.1.4.2. Proces trenowania i wyniki
Fragment kodu służący do trenowania modelu na zbiorze ECG200 wygląda następująco:
Ecg200Model model = new(commonRandom);
LearningRate learningRate = new ExponentialDecayLearningRate(InitialLearningRate, FinalLearningRate, 0);
Trainer<float[,,], float[,]> trainer = new(
model,
new AdamOptimizer(learningRate, AdamBeta1, AdamBeta2),
random: commonRandom,
logger: logger
);
trainer.Fit(
dataSource,
s_evalFunction,
epochs: Epochs,
evalEveryEpochs: EvalEveryEpochs,
logEveryEpochs: LogEveryEpochs,
batchSize: BatchSize,
saveParamsOnBestLoss: true,
showTrainEval: true
);
Listing 7.3. Kodu służący do trenowania modelu na zbiorze ECG200
Po przeprowadzeniu procesu trenowania model osiągnął wyniki przedstawione na rysunku 7.1.
Rysunek 7.1. Wynik trenowania modelu ECG200
Podstawowe metryki osiągnięte przez model to:
- Train loss (average): 0,16014086
- Test loss: 0,3037759
- Train eval: 96,00%
- Test eval: 89,00%
7.1.4.2.1. Przykłady klasyfikacji
Zilustrujmy teraz sprawność klasyfikacyjną wytrenowanego modelu sieci konwolucyjnej 1D. Poniższa tabela przedstawia 8 przykładowych obrazów z danych testowych wraz z przewidywaniami modelu. Rozpatrujemy 4 kategorie:
- Obrazy, które zostały poprawnie sklasyfikowane jako klasa 1 (zdrowy)
- Obrazy, które zostały poprawnie sklasyfikowane jako klasa 0 (chory)
- Obrazy, które zostały błędnie sklasyfikowane jako klasa 0 (chory), podczas gdy ich prawdziwa klasa to 1 (zdrowy)
- Obrazy, które zostały błędnie sklasyfikowane jako klasa 1 (zdrowy), podczas gdy ich prawdziwa klasa to 0 (chory)
| Kategoria | Obrazy testowe | Etykiety (prawdziwa klasa) | Przewidywanie modelu | Poprawność klasyfikacji | Liczba przypadków w danej kategorii |
|---|---|---|---|---|---|
| 1 | 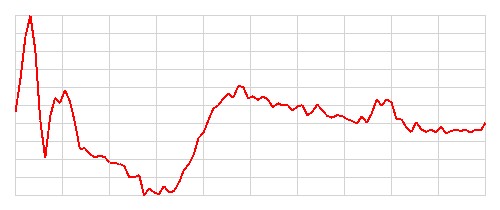 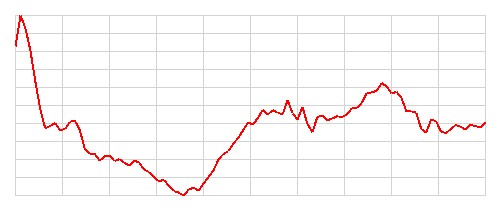 |
Zdrowy | Zdrowy | Poprawna | 60 |
| 2 | 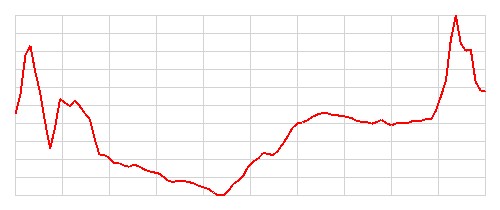 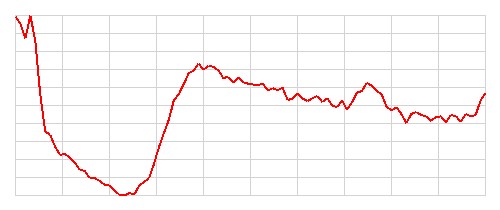 |
Chory | Chory | Poprawna | 29 |
| 3 | 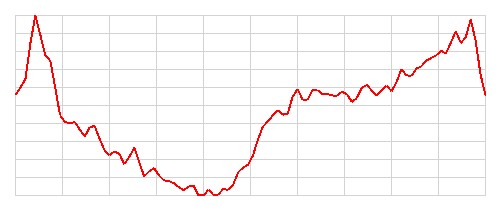 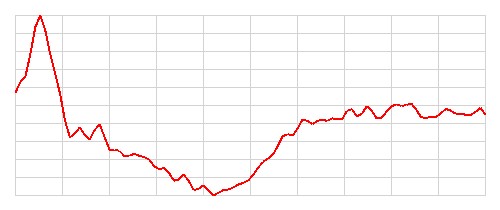 |
Zdrowy | Chory | Błędna | 4 |
| 4 | 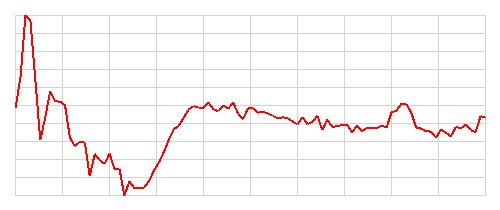  |
Chory | Zdrowy | Błędna | 7 |
| Razem | 100 |
Tabela 7.1. Przykłady klasyfikacji dla modelu ECG200
Szczerze mówiąc, nie potrafię odróżnić obrazów EKG przedstawiających osoby zdrowe od tych przedstawiających osoby chore. Nie potrafię również znaleźć żadnego wzorca, który pozwoliłby mi z góry przewidzieć, które obrazy zostaną poprawnie sklasyfikowane, a które nie. Wydaje się, że model radzi sobie dobrze z większością obrazów, ale w kilkunastu (11) przypadkach popełnia błędy. Zostańmy jak na razie z tą tajemnicą, być może wrócimy do tematu później.
7.2. Sieci konwolucyjne 2D
Sieci konwolucyjne 2D (ang. 2D Convolutional Neural Networks) są uogólnieniem sieci konwolucyjnych 1D, które zostały omówione w poprzednim podpunkcie. W sieciach konwolucyjnych 2D operacja konwolucji jest wykonywana wzdłuż dwóch osi (np. wysokości i szerokości obrazu), co pozwala na wykrywanie lokalnych wzorców przestrzennych w danych wejściowych.
Dwuwymiarowe sieci konwolucyjne są szeroko stosowane w zadaniach związanych z analizą obrazów, takich jak klasyfikacja, detekcja obiektów czy segmentacja. W sieciach tego rodzaju operacja konwolucji jest wykonywana wzdłuż dwóch osi (np. wysokości i szerokości obrazu), co pozwala na wykrywanie lokalnych wzorców przestrzennych w danych wejściowych.
Prześledźmy w tym podpunkcie, jak działa operacja konwolucji 2D. Załóżmy, że mamy ciąg danych wejściowych \(X\) o wymiarach 3 * 3:
Mamy również filtr \(W\) o wymiarach 2 * 2:
Operacja konwolucji 2D polega na przesuwaniu filtra wzdłuż dwóch wymiarów (wysokości i szerokości) ciągu wejściowego i obliczaniu sumy ważonej elementów wejściowych i odpowiadających im wag filtra. Tworzona więc jest macierz wyjściowa \(Y\) o wymiarach 2 * 2, która wygląda następująco:
gdzie jej elementy obliczane są wg poniższego wzoru:
przy czym \(i\) i \(j\) to indeksy wierszy i kolumn ciągu wejściowego, przyjmujące wartości od 1 do 2, a indeksy wagi filtra są ustalone.
Podobnie jak w przypadku konwolucji 1D, w przypadku konwolucji 2D również można stosować techniki takie jak padding, stride, dilation oraz pooling w celu kontrolowania rozmiaru wyjścia, zwiększenia zasięgu wykrywania wzorców lub zmniejszenia wymiarowości danych.
I to tyle - to już cała filozofia 😎
7.2.1. Obliczanie gradientów
Gradient względem ciągu wejściowego \(X\) można obliczyć jako konwolucję gradientu \(dY\) z odwróconym filtrem \(W\):
przy czym odwrócony (odwrócona kolejność wierszy i odwrócona kolejność kolumn) filtr \(W_{\text{flipped}}\) jest definiowany jako:
Gradient względem filtra \(W\) można obliczyć jako konwolucję ciągu wejściowego \(X\) z gradientem \(dY\):
7.2.1.1. Przykład liczbowy
Przeliczmy teraz na konkretnych wartościach wyjście \(Y\) oraz gradienty względem wejścia i parametrów dla następujących danych:
- macierz wejściowa \(X\):
- filtr \(W\):
- gradient \(dY\):
Dla powyższych wartości oraz \(padding = 1\) otrzymujemy macierz wyjściową \(Y\):
gdzie np. wartość środkowa (\(y_{22} = 12\)) jest wyliczana tak:
\(y_{22} = 1 \cdot 1 + 0 \cdot 2 + 0 \cdot 3 + 1 \cdot 4 + 0 \cdot 5 + 0 \cdot 6 + 1 \cdot 7 + 0 \cdot 8 + 0 \cdot 9 = 12\)
Gradient względem wejścia \(dX\) można obliczyć jako konwolucję gradientu \(dY\) z filtrem \(W\) odwróconym:
Gradient względem filtra \(W\) można obliczyć jako konwolucję ciągu wejściowego \(X\) z gradientem \(dY\):
7.2.2 Implementacja w bibliotece NeuralNetworks
Sieci konwolucyjne 2D wykorzystują w bibliotece NeuralNetworks trzy metody służące do uczenia i inferencji: Convolve2DOutput, Convolve2DInputGradient oraz Convolve2DParamGradient. Metody te są wykorzystywane odpowiednio do obliczania wyjścia warstwy konwolucyjnej, obliczania gradientów względem wejścia oraz obliczania gradientów względem parametrów (filtrów). Są one zaimplementowane w różnych wersjach zależnych od zaplecza obliczeniowego.
W wersji najbardziej podstawowej metody te wyglądają następująco:
public virtual float[,,,] Convolve2DOutput(float[,,,] input, float[,,,] weights, int paddingHeight, int paddingWidth, int strideHeight = 1, int strideWidth = 1, int dilatationHeight = 0, int dilatationWidth = 0)
{
int batchSize = input.GetLength(0);
int inputChannels = input.GetLength(1);
int inputHeight = input.GetLength(2);
int inputWidth = input.GetLength(3);
int outputChannels = weights.GetLength(1);
int kernelHeight = weights.GetLength(2);
int kernelWidth = weights.GetLength(3);
Debug.Assert(weights.GetLength(0) == inputChannels);
int effectiveInputHeight = inputHeight + 2 * paddingHeight;
int effectiveInputWidth = inputWidth + 2 * paddingWidth;
int effectiveKernelHeight = dilatationHeight * (kernelHeight - 1) + kernelHeight;
int effectiveKernelWidth = dilatationWidth * (kernelWidth - 1) + kernelWidth;
int outputHeight = (effectiveInputHeight - effectiveKernelHeight) / strideHeight + 1;
int outputWidth = (effectiveInputWidth - effectiveKernelWidth) / strideWidth + 1;
float[,,,] output = new float[batchSize, outputChannels, outputHeight, outputWidth];
for (int b = 0; b < batchSize; b++)
{
for (int oc = 0; oc < outputChannels; oc++)
{
for (int oh = 0; oh < outputHeight; oh++)
{
for (int ow = 0; ow < outputWidth; ow++)
{
float sum = 0.0f;
for (int ic = 0; ic < inputChannels; ic++)
{
for (int kh = 0; kh < kernelHeight; kh++)
{
int ih = oh * strideHeight + kh * dilatationHeight - paddingHeight;
for (int kw = 0; kw < kernelWidth; kw++)
{
int iw = ow * strideWidth + kw * dilatationWidth - paddingWidth;
if (ih >= 0 && ih < inputHeight && iw >= 0 && iw < inputWidth)
{
sum += input[b, ic, ih, iw] * weights[ic, oc, kh, kw];
}
}
}
}
output[b, oc, oh, ow] = sum;
}
}
}
}
return output;
}
public virtual float[,,,] Convolve2DInputGradient(float[,,,] input, float[,,,] weights, float[,,,] outputGradient, int paddingHeight, int paddingWidth, int strideHeight = 1, int strideWidth = 1, int dilatationHeight = 0, int dilatationWidth = 0)
{
int batchSize = outputGradient.GetLength(0);
int inputChannels = input.GetLength(1);
int inputHeight = input.GetLength(2);
int inputWidth = input.GetLength(3);
int outputChannels = outputGradient.GetLength(1);
int outputGradientHeight = outputGradient.GetLength(2);
int outputGradientWidth = outputGradient.GetLength(3);
int kernelHeight = weights.GetLength(2);
int kernelWidth = weights.GetLength(3);
Debug.Assert(weights.GetLength(0) == inputChannels);
float[,,,] inputGradient = new float[batchSize, inputChannels, inputHeight, inputWidth];
for (int b = 0; b < batchSize; b++)
{
for (int ic = 0; ic < inputChannels; ic++)
{
for (int ih = 0; ih < inputHeight; ih++)
{
for (int iw = 0; iw < inputWidth; iw++)
{
float sum = 0.0f;
for (int oc = 0; oc < outputChannels; oc++)
{
for (int kh = 0; kh < kernelHeight; kh++)
{
for (int kw = 0; kw < kernelWidth; kw++)
{
int oh = Math.DivRem(ih + paddingHeight - kh * dilatationHeight, strideHeight, out int remH);
int ow = Math.DivRem(iw + paddingWidth - kw * dilatationWidth, strideWidth, out int remW);
if (oh >= 0 && oh < outputGradientHeight
&& (ih + paddingHeight - kh * (dilatationHeight + 1)) % strideHeight == 0
&& ow >= 0 && ow < outputGradientWidth
&& (iw + paddingWidth - kw * (dilatationWidth + 1)) % strideWidth == 0
)
{
sum += outputGradient[b, oc, oh, ow] * weights[ic, oc, kh, kw];
}
}
}
}
inputGradient[b, ic, ih, iw] = sum;
}
}
}
}
return inputGradient;
}
public virtual float[,,,] Convolve2DParamGradient(float[,,,] input, float[,,,] outputGradient, int kernelHeight, int kernelWidth, int paddingHeight, int paddingWidth, int strideHeight = 1, int strideWidth = 1, int dilatationHeight = 0, int dilatationWidth = 0)
{
int batchSize = outputGradient.GetLength(0);
int inputChannels = input.GetLength(1);
int inputHeight = input.GetLength(2);
int inputWidth = input.GetLength(3);
int outputChannels = outputGradient.GetLength(1);
int outputGradientHeight = outputGradient.GetLength(2);
int outputGradientWidth = outputGradient.GetLength(3);
float[,,,] paramGradient = new float[inputChannels, outputChannels, kernelHeight, kernelWidth];
for (int b = 0; b < batchSize; b++)
{
for (int ic = 0; ic < inputChannels; ic++)
{
for (int oc = 0; oc < outputChannels; oc++)
{
for (int kh = 0; kh < kernelHeight; kh++)
{
for (int kw = 0; kw < kernelWidth; kw++)
{
float sum = 0.0f;
for (int oh = 0; oh < outputGradientHeight; oh++)
{
for (int ow = 0; ow < outputGradientWidth; ow++)
{
int ih = oh * strideHeight + kh * dilatationHeight - paddingHeight;
int iw = ow * strideWidth + kw * dilatationWidth - paddingWidth;
if (ih >= 0 && ih < inputHeight && iw >= 0 && iw < inputWidth)
{
sum += outputGradient[b, oc, oh, ow] * input[b, ic, ih, iw];
}
}
}
paramGradient[ic, oc, kh, kw] += sum;
}
}
}
}
}
return paramGradient;
}
Listing 7.4. Podstawowa implementacja metod konwolucyjnych w bibliotece NeuralNetworks
W powyższym kodzie użyte zostały następujące zmienne:
input- odpowiednik \(X\) z uwzględnieniem batch size i kanałów wejściowych (o wymiarach [batchSize, inputChannels, inputHeight, inputWidth])weights- odpowiednik \(W\) z uwzględnieniem kanałów wejściowych i wyjściowych (o wymiarach [inputChannels, outputChannels, kernelHeight, kernelWidth])outputGradient- odpowiednik \(dY\) (o wymiarach [batchSize, outputChannels, outputGradientHeight, outputGradientWidth])inputGradient- odpowiednik \(dX\) (o wymiarach [batchSize, inputChannels, inputHeight, inputWidth])paramGradient- odpowiednik \(dW\) (o wymiarach [inputChannels, outputChannels, kernelHeight, kernelWidth])paddingHeight,paddingWidth,strideHeight,strideWidth,dilatationHeight,dilatationWidth- parametry konwolucji
7.2.3. Przykład zastosowania: klasyfikacja obrazów MNIST
Sprawdźmy teraz jak sieć konwolucyjna 2D poradzi sobie z zadaniem klasyfikacji danych na zbiorze MNIST, który w poprzednim rozdziale analizowaliśmy za pomocą prostej sieci z warstwami gęstymi.
Note
Poniższy kod w pełnej wersji znajduje się na GitHub.
7.2.3.1. Architektura modelu
Architektura omawianej sieci konwolucyjnej jest następująca:
class MnistConvModel(SeededRandom? random)
: BaseModel<float[,,,], float[,]>(new SoftmaxCrossEntropyLoss(), random)
{
protected override LayerListBuilder<float[,,,], float[,]> CreateLayerListBuilder()
{
GlorotInitializer initializer = new(Random);
return
AddLayer(new Conv2DLayer(
filters: 32,
kernelSize: 5,
activationFunction: new LeakyReLU4D(),
paramInitializer: initializer,
dropout: new Dropout4D(0.8f, Random)
))
.AddLayer(new FlattenLayer())
.AddLayer(new DenseLayer(10, new Linear(), initializer));
}
}
Listing 7.5. Definicja modelu MNIST z siecią konwolucyjną
Model ten składa się z warstwy konwolucyjnej z 32 filtrami o rozmiarze 5x5, wykorzystującej funkcję aktywacji Leaky ReLU oraz mechanizm dropout (o współczynniku keepProb = 0.8), warstwy spłaszczającej (Flatten) oraz warstwy wyjściowej używającej funkcji liniowej (czyli de facto bez funkcji aktywacji). Funkcją straty jest Softmax Cross-Entropy.
Warstwa Conv2DLayer składa się z operacji Conv2D oraz funkcji aktywacji, podanej w parametrze activationFunction.
7.2.3.2. Proces i wyniki trenowania
Proces trenowania jest analogiczny do przedstawionego w rozdziale 6.2.4.. Różnica polega na tym, że dane wejściowe muszą mieć kształt 4-wymiarowej tablicy (batch size, wysokość obrazu, szerokość obrazu, liczba kanałów). W przypadku obrazów MNIST liczba kanałów wynosi 1 (obrazy są w skali szarości). W związku z tym przygotowanie danych wejściowych wygląda następująco:
(float[,,,] xTrain, float[,] yTrain) = Split(train);
(float[,,,] xTest, float[,] yTest) = Split(test);
Listing 7.6. Podział danych MNIST na cechy wejściowe i etykiety dla sieci konwolucyjnej
gdzie funkcja Split została zaimplementowana jak poniżej:
private static (float[,,,] xTest, float[,] yTest) Split(float[,] source)
{
// Split into xTest (all columns except the first one) and yTest (a one-hot table from the first column with values from 0 to 9).
float[,] xTest2D = source.GetColumns(1..source.GetLength(1));
float[,] yTest = source.GetColumn(0);
Debug.Assert(xTest2D.GetLength(1) == 28 * 28);
// Convert yTest to a one-hot table.
int yTestRows = yTest.GetLength(0);
float[,] oneHot = new float[yTestRows, 10];
for (int row = 0; row < yTestRows; row++)
{
int value = Convert.ToInt32(yTest[row, 0]);
oneHot[row, value] = 1f;
}
int xTestRows = xTest2D.GetLength(0);
int xTestCols = xTest2D.GetLength(1);
float[,,,] xTest4D = new float[xTestRows, 1, 28, 28];
for (int row = 0; row < xTestRows; row++)
{
for (int col = 0; col < xTestCols; col++)
{
//int x = col % 28;
//int y = col / 28;
xTest4D[row, 0 /* one input channel */, col / 28, col % 28] = xTest2D[row, col];
}
}
return (xTest4D, oneHot);
}
Listing 7.7. Implementacja funkcji Split dla sieci konwolucyjnej
Wynik trenowania modelu MNIST z siecią konwolucyjną przedstawiono poniżej.
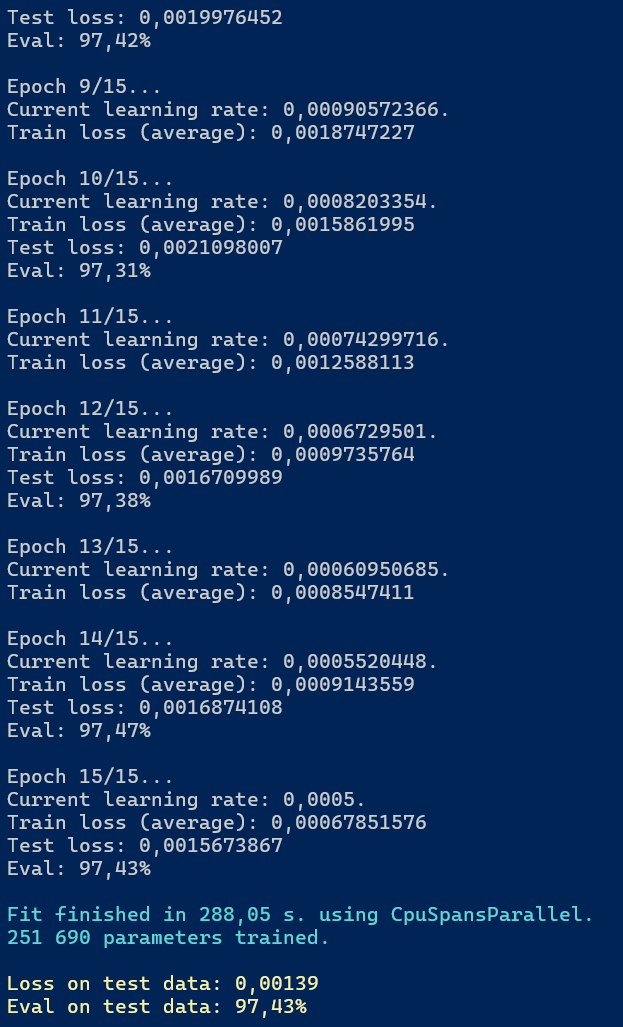
Rysunek 7.2. Rezultat trenowania modelu MNIST z siecią konwolucyjną
Dla zbioru uczącego wartość straty po 15 epokach wyniosła (średnio) 0,000679. Dla zbioru testowego wartość straty wyniosła ostatecznie 0,00139, a dokładność - 97,43%.
7.2.3.2.1. Przykłady klasyfikacji
Podobnie jak to zrobiliśmy poprzednio zilustrujemy teraz sprawność klasyfikacyjną wytrenowanego modelu sieci konwolucyjnej 2D za pomocą poniższej tabeli. Tabela ta przedstawia 8 przykładowych obrazów z danych testowych wraz z przewidywaniami modelu. Rozpatrywane kategorie są identyczne z tymi zdefiniowanymi w rozdziale 6.2.5.1.
| Kategoria | Obrazy testowe | Etykiety (prawdziwa klasa) | Przewidywanie modelu | Poprawność klasyfikacji | Liczba przypadków w danej kategorii |
|---|---|---|---|---|---|
| 1 |   |
3 | 3 | Poprawna | 989 |
| 2 |   |
7, 6 | 7, 6 | Potencjalnie poprawna | 8967 |
| 3 |   |
3 | 7, 2 | Błędna | 23 |
| 4 |   |
5, 0 | 3 | Błędna | 21 |
| Razem | 10 000 |
Tabela 7.2. Przykłady klasyfikacji dla modelu MNIST z siecią konwolucyjną
Jak widać, część klasyfikacji (zidentyfikowanych jako pierwsze w zbiorze testowym) pokrywa się z klasyfikacjami uzyskanymi przez model z warstwami gęstymi, ale występują także różnice (klasyfikacje zidentyfikowane jako ostatnie). Występuje również różnica w liczebności poszczególnych kategorii.
7.3. Podsumowanie
W tym rozdziale omówiliśmy działanie sieci konwolucyjnych 1D i 2D, które to sieci stanowią narzędzia służące do analizy danych sekwencyjnych i obrazów.
Przeanalizowaliśmy, jak działają operacje konwolucji, paddingu, stridu, dilatacji oraz pooling, a także jak obliczać gradienty dla tych operacji. Następnie przedstawiliśmy implementację tych operacji w bibliotece NeuralNetworks oraz pokazaliśmy przykłady zastosowania sieci konwolucyjnych do klasyfikacji sygnałów EKG z zbioru ECG200 oraz do klasyfikacji obrazów z zbioru MNIST.
Created: 2026-02-09
Last modified: 2026-04-12
Title: 7. Konwolucyjne sieci neuronowe
Tags: [C#] [Sieci neuronowe] [Biblioteka] [NeuralNetworks] [MNIST] [CNN] [Convolutional Neural Networks] [ECG200]