6. Użycie biblioteki NeuralNetworks
W poprzednim rozdziale przedstawiona została biblioteka NeuralNetworks - jej struktura, kluczowe komponenty oraz sposób definiowania, trenowania i wykorzystywania modeli sieci neuronowych. Omówione zostały elementy niskopoziomowe, takie jak operacje macierzowe i funkcje straty, a także wyższego poziomu abstrakcje obejmujące modele, warstwy, operacje, optymalizatory oraz proces trenowania. Celem tamtego rozdziału było przedstawienie względnie elastycznego, ogólnego narzędzia, które ułatwi dalszą, praktyczną pracę z sieciami neuronowymi bez konieczności każdorazowego implementowania ich od podstaw.
W tym natomiast rozdziale przejdziemy do przykładów jej praktycznego zastosowania. W pierwszej kolejności skupimy się na danych Boston Housing, które znamy z rozdziałów 3 i 4, a następnie przeanalizujemy inny zbiór danych - MNIST - który jest standardowym zbiorem danych do klasyfikacji obrazów.
6.1. Analiza danych Boston Housing
Spróbujmy więc ponownie przeanalizować dane ze zbioru Boston Housing. Tym razem zamiast implementować sieć neuronową od podstaw, wykorzystamy do tego celu bibliotekę NeuralNetworks.
Note
Poniższy kod w pełnej wersji znajduje się na GitHub
6.1.1. Architektura modelu
Model naszej sieci neuronowej możemy zdefiniować poprzez utworzenie klasy dziedziczącej po BaseModel<TInputData, TPrediction> i nadpisanie metody CreateLayerListBuilder, w której określamy jego strukturę (liczbę warstw, liczbę neuronów w każdej warstwie oraz funkcje aktywacji). Nasz model będzie miał jedną warstwę ukrytą z czterema neuronami i funkcją aktywacji Tanh oraz warstwę wyjściową z jednym neuronem i funkcją liniową. W bibliotece NeuralNetworks nie musimy jawnie deklarować warstwy wejściowej, ponieważ jest ona implikowana przez kształt danych wejściowych.
class BostonHousingModel(SeededRandom? random)
: BaseModel<float[,], float[,]>(new MeanSquaredError(), random)
{
protected override LayerListBuilder<float[,], float[,]> CreateLayerListBuilder()
{
GlorotInitializer initializer = new(Random);
return AddLayer(new DenseLayer(4, new Tanh2D(), initializer))
.AddLayer(new DenseLayer(1, new Linear(), initializer));
}
}
Listing 6.1. Definicja modelu sieci neuronowej do przewidywania cen w zbiorze Boston Housing
6.1.2. Dane źródłowe
SimpleDataSource<float[,], float[,]> dataSource = new(XTrain, YTrain, XTest, YTest);
Tablice XTrain, YTrain, XTest i YTest zostały przygotowane w sposób analogiczny do przedstawionego na listingach 3.1 i 3.2. Między innymi zostały one poddane normalizacji za pomocą procedury StandardizeByColumns.
6.1.3. Trenowanie modelu
Trenowanie modelu odbywa się poprzez utworzenie instancji klasy Trainer<TInputData, TPrediction>, przekazanie do niej modelu i optymalizatora, a następnie wywołanie metody Fit wraz z dostawcą danych i parametrami uczenia/logowania, jak pokazano poniżej.
BostonHousingModel model = new(commonRandom);
ExponentialDecayLearningRate learningRate = new(
initialLearningRate: 0.0009f,
finalLearningRate: 0.0005f
);
Trainer2D trainer = new(
model,
new GradientDescentMomentumOptimizer(learningRate, 0.9f),
random: commonRandom,
logger: logger
);
trainer.Fit(
dataSource,
epochs: 48_000,
evalEveryEpochs: 2_000,
logEveryEpochs: 2_000,
batchSize: 400
);
Listing 6.2. Trenowanie modelu sieci neuronowej do przewidywania cen w zbiorze Boston Housing
6.1.4. Rezultat trenowania
Po zakończeniu trenowania modelu uzyskaliśmy wyniki przedstawione na poniższej ilustracji.
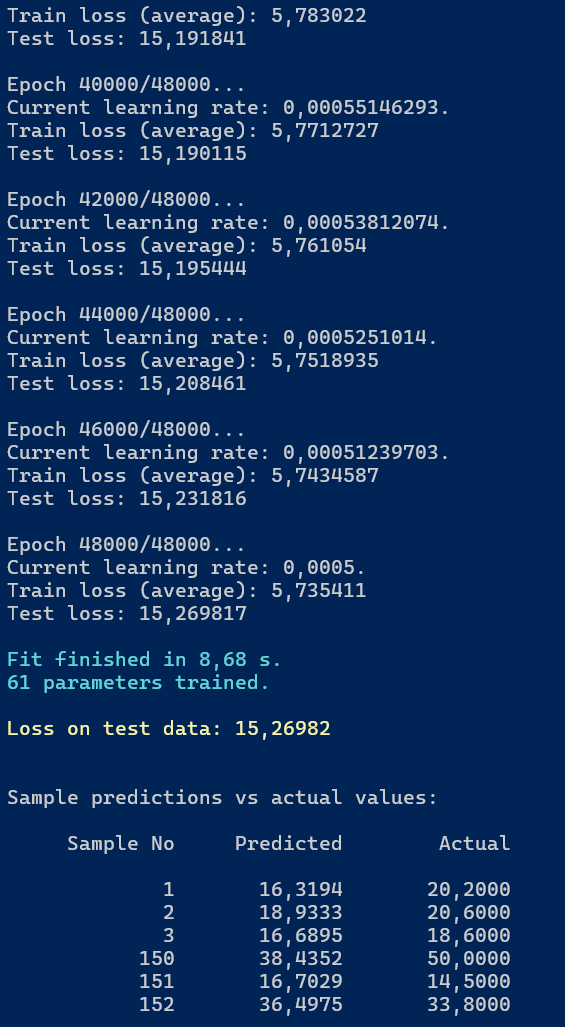
Rysunek 6.1. Rezultat trenowania modelu sieci neuronowej do przewidywania cen w zbiorze Boston Housing
Ponieważ jest to już nasze ostatnie spotkanie z danymi Boston Housing, pozwolimy sobie na krótkie podsumowanie wyników.
| Metoda | Funkcja aktywacji | Optymalizator | MSE na zbiorze treningowym | MSE na zbiorze testowym | Czas treningu [s] |
|---|---|---|---|---|---|
| Regresja liniowa (rozdział 3) | Linear | SGD | 19,44 | 29,49 | 0,87 |
| Pierwsza sieć neuronowa (rozdział 4) | Sigmoid | SGD | 7,72 | 17,44 | 4,37 |
| Biblioteka NeuralNetworks (rozdział 6) | Tanh | SGD z momentum | 5,74 | 15,27 | 8,23 |
Tabela 6.1. Porównanie wyników różnych metod na danych Boston Housing (48 tys. epok)
6.2. Analiza danych MNIST
Przejdźmy teraz do analizy zbioru danych MNIST, zawierającego obrazy odręcznie pisanych cyfr, który tradycyjnie stanowi punkt odniesienia w zadaniach klasyfikacji obrazów.
6.2.1. Zbiór danych MNIST
Podobnie jak zbiór Boston Housing, dane MNIST są swobodnie dostępne i stosowane w literaturze. Zbiór ten zawiera 70 000 obrazów odręcznie pisanych cyfr (0-9), podzielonych na 60 000 obrazów treningowych i 10 000 obrazów testowych. Każdy obraz ma rozmiar 28x28 pikseli i jest reprezentowany jako macierz wartości szarości (od 0 do 255). Celem zadania jest przypisanie każdego obrazu do jednej z dziesięciu klas odpowiadających cyfrom od 0 do 9 (problem klasyfikacji wieloklasowej z pojedynczą etykietą, ang. multi-class single-label classification).
W naszych eksperymentach będziemy pracować na znacznie mniejszym zbiorze uczącym, zawierającym jedynie 20 000 obrazów (plus 10 000 obrazów testowych). Zbiór ten znajduje się na GitHub.

Rysunek 6.2. Przykładowe obrazy z zestawu danych MNIST (źródło: Wikipedia)
Analizę danych MNIST przeprowadzimy w tym przypadku z wykorzystaniem prostej sieci z warstwami gęstymi (analizę za pomocą sieci konwolucyjnej przedstawimy w rozdziale 7).
Note
Poniższy kod w pełnej wersji znajduje się na GitHub.
6.2.2. Architektura modelu
Architektura omawianej sieci jest następująca:
class MnistDenseModel(SeededRandom? random)
: BaseModel<float[,], float[,]>(new SoftmaxCrossEntropyLoss(), random)
{
protected override LayerListBuilder<float[,], float[,]> CreateLayerListBuilder()
{
GlorotInitializer initializer = new(Random);
return
AddLayer(new DenseLayer(178, new LeakyReLU2D(), initializer, new Dropout2D(0.8f, Random)))
.AddLayer(new DenseLayer(46, new LeakyReLU2D(), initializer, new Dropout2D(0.8f, Random)))
.AddLayer(new DenseLayer(10, new Linear(), initializer));
}
}
Listing 6.3. Definicja modelu MNIST z warstwami gęstymi
Model ten składa się z 3 warstw gęstych, które mają odpowiednio 178, 46 i 10 neuronów. Pierwsze dwie warstwy wykorzystują funkcje aktywacji Leaky ReLU oraz mechanizm dropout (o współczynniku keepProb = 0.8), natomiast warstwa wyjściowa (produkująca logity) używa funkcji liniowej. Funkcją straty jest Softmax Cross-Entropy.
Wagi warstw gęstych sieci są inicjalizowane za pomocą inicjalizatora Glorot (Xavier).
6.2.3. Dane źródłowe
Dane (zbiór treningowy i testowy odręcznie pisanych cyfr) wczytywane są z pliku CSV:
float[,] train = LoadCsv("..\\..\\..\\..\\..\\data\\MNIST\\mnist_train_small.csv");
float[,] test = LoadCsv("..\\..\\..\\..\\..\\data\\MNIST\\mnist_test.csv");
Listing 6.4. Wczytywanie danych MNIST z plików CSV
Następnie wczytane dane są dzielone na cechy wejściowe (piksele obrazów) oraz etykiety (cyfry od 0 do 9):
(float[,] xTrain, float[,] yTrain) = Split(train);
(float[,] xTest, float[,] yTest) = Split(test);
Listing 6.5. Podział danych MNIST na cechy wejściowe i etykiety
W kolejnym kroku cechy wejściowe są normalizowane do średniej 0 oraz odchylenia standardowego 1:
float mean = xTrain.Mean();
xTrain.AddInPlace(-mean);
xTest.AddInPlace(-mean);
float stdDev = xTrain.StdDev();
xTrain.DivideInPlace(stdDev);
xTest.DivideInPlace(stdDev);
Listing 6.6. Normalizacja cech wejściowych danych MNIST
Tak obrobione dane są następnie przekazywane do dostawcy danych treningowych i testowych:
SimpleDataSource<float[,], float[,]> dataSource = new(xTrain, yTrain, xTest, yTest);
Listing 6.7. Definicja dostawcy danych treningowych i testowych dla danych MNIST
Zmienna dataSource jest przekazywana do metody Fit trenera, jak pokazano na listingu 6.8.
6.2.4. Trenowanie modelu
Za proces trenowania odpowiada klasa Trainer<TInputData, TPrediction>. Przykładowy sposób jej utworzenia oraz wywołania metody Fit przedstawiono poniżej.
SeededRandom commonRandom = new(44);
MnistDenseModel model = new(commonRandom);
Trainer<float[,], float[,]> trainer = new(
model,
new AdamOptimizer(learningRate: new ExponentialDecayLearningRate(0.002f, 0.0005f, warmupSteps: 10), beta1: 0.89f, beta2: 0.99f),
random: commonRandom,
logger: logger
);
trainer.Fit(
dataSource,
s_evalFunction,
epochs: 15,
evalEveryEpochs: 2,
logEveryEpochs: 1,
batchSize: 400,
displayDescriptionOnStart: true
);
Listing 6.8. Trenowanie modelu MNIST z warstwami gęstymi
Model jest trenowany przez 15 epok z wykorzystaniem optymalizatora Adam z wykładniczym spadkiem współczynnika uczenia (początkowy współczynnik uczenia = 0.002, końcowy współczynnik uczenia = 0.0005). Rozmiar batcha wynosi 400.
6.2.5. Rezultat trenowania
Poniżej przedstawiono efekt trenowania modelu MNIST z warstwami gęstymi.
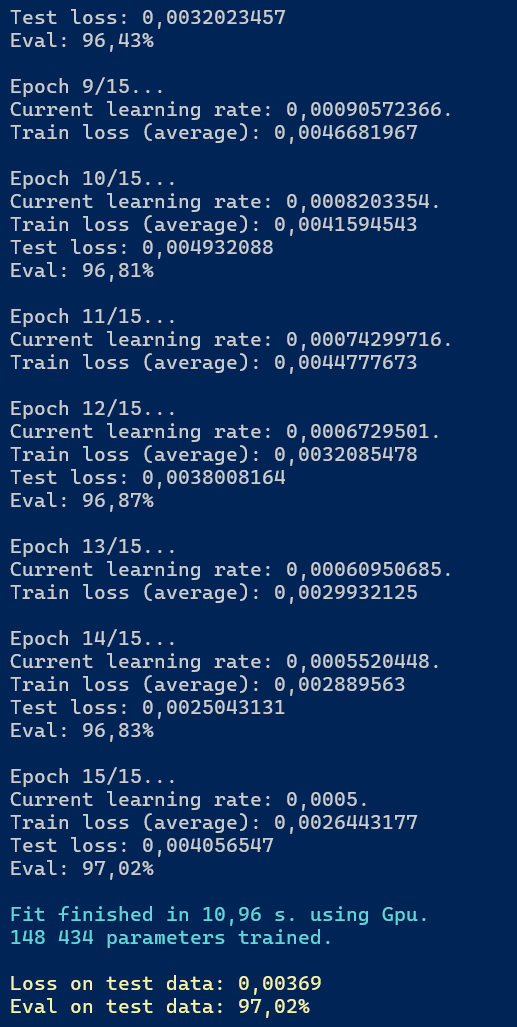
Rysunek 6.3. Rezultat trenowania modelu MNIST z warstwami gęstymi
Dla zbioru uczącego wartość straty po 15 epokach wyniosła (średnio z kolejnych batchów) 0,002644. Dla zbioru testowego wartość straty wyniosła ostatecznie 0,00369, a dokładność - 97,02% (w tylu procentach przypadków model prawidłowo sklasyfikował obraz).
W procesie trenowania wykorzystano zaplecze obliczeniowe OperationBackendType.Gpu i jest to informacja istotna w kontekście powtórzenia powyższych wyników. W przypadku użycia zaplecza OperationBackendType.Cpu... lub OperationBackendType.CpuSpansParallel wyniki mogą się różnić m.in. ze względu na różnice w kolejności obliczeń. Wyniki mogą się również zmieniać pomiędzy poszczególnymi wywołaniami procesu trenowania, ponieważ dla zaplecza OperationBackendType.CpuSpansParallel oraz OperationBackendType.Gpu operacje macierzowe są wykonywane równolegle, w niedeterministycznej kolejności, co może prowadzić do różnic w wynikach z powodu ograniczonej precyzji reprezentacji liczb zmiennoprzecinkowych. W powyższym przykładzie pierwsze wywołanie obliczenia straty na danych testowych w epoce 15. wygenerowało inny wynik (0,00406) niż obliczenie końcowe (0,00369). Dla zapleczy deterministycznych taka sytuacja nie będzie miała miejsca.
6.2.5.1. Przykłady klasyfikacji
Zilustrujmy teraz działanie wytrenowanego wg powyższego opisu modelu na przykładach z danych testowych. W poniższej tabeli przedstawiono 4 przykładowe obrazy z danych testowych wraz z przewidywaniami modelu. Uwzględniliśmy 4 kategorie przypadków:
- obraz przedstawia cyfrę 3 i model prawidłowo go sklasyfikował
- obraz nie przedstawia cyfry 3 i model prawidłowo sklasyfikował go jako nie-3
- obraz przedstawia cyfrę 3, ale model błędnie sklasyfikował go jako nie-3
- obraz nie przedstawia cyfry 3, ale model błędnie sklasyfikował go jako 3.
Cyfrę "3" wybrano celowo, ponieważ jest ona jedną z trudniejszych do sklasyfikowania cyfr w zbiorze MNIST i jest często mylona z innymi cyframi, co pozwala lepiej zobrazować działanie modelu.
| Kategoria | Obrazy testowe | Etykiety (prawdziwa klasa) | Przewidywanie modelu | Poprawność klasyfikacji | Liczba przypadków w danej kategorii |
|---|---|---|---|---|---|
| 1 |   |
3 | 3 | Poprawna | 983 |
| 2 |  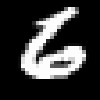 |
7, 6 | 7, 6 | Potencjalnie poprawna | 8954 |
| 3 |  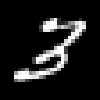 |
3 | 7, 2 | Błędna | 36 |
| 4 |   |
5, 6 | 3 | Błędna | 27 |
| Razem | 10 000 |
Tabela 6.2. Przykłady klasyfikacji modelu MNIST z warstwami gęstymi
6.2.6. Zapis i odczyt modelu
Po zakończeniu trenowania model można zapisać do pliku za pomocą metody SaveParams(string, string?). Przykładowy sposób zapisu modelu oraz parametrów normalizacji przedstawiono poniżej.
private const string ModelName = "MnistDenseModel";
string modelPath = $"{ModelName}.json";
model.SaveParams(modelPath, "Final trained model.");
File.WriteAllText($"{ModelName}.stats", $"{mean};{stdDev}");
Listing 6.9. Zapis modelu MNIST z warstwami gęstymi do pliku
Ponieważ model MNIST z warstwami gęstymi wymaga normalizacji danych wejściowych, dodatkowo zapisywane są parametry tej normalizacji (średnia i odchylenie standardowe) do osobnego pliku tekstowego (*.stats). Jest to niezbędne do wykorzystania modelu do pracy na nowych danych, gdyż muszą one zostać znormalizowane tymi samymi parametrami.
Początek pliku JSON z zapisanym modelem wygląda następująco:
{
"Version": 1,
"ArchitectureDescription": [
"Model",
" Type: NeuralNetworksExamples.MnistDenseModel",
" Random: SeededRandom (seed=44)",
" LossFunction: SoftmaxCrossEntropyLoss (eps=1E-07)",
" Layers",
" DenseLayer (neurons=178, activation=LeakyReLU2D (alfa=0,01, beta=1), paramInitializer=GlorotInitializer (seed=44), dropout=Dropout2D (keepProb=0,8, seed=44))",
" DenseLayer (neurons=46, activation=LeakyReLU2D (alfa=0,01, beta=1), paramInitializer=GlorotInitializer (seed=44), dropout=Dropout2D (keepProb=0,8, seed=44))",
" DenseLayer (neurons=10, activation=Linear, paramInitializer=GlorotInitializer (seed=44), dropout=)"
],
"Comment": "Final trained model.",
"Input": {
"InputType": "System.Single[,], System.Private.CoreLib, Version=10.0.0.0, Culture=neutral, PublicKeyToken=7cec85d7bea7798e",
"Shape": [
400,
784
]
},
"Layers": [
{
"LayerType": "NeuralNetworks.Layers.DenseLayer, NeuralNetworks, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null",
"Operations": [
{
"OperationType": "NeuralNetworks.Operations.Parameterized.WeightMultiply, NeuralNetworks, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null",
"Parameters": {
"Shape": [
784,
178
],
"Values": [
-0.031858373,
-0.04776369,
0.0038630932,
0.03661709,
0.031841997,
-0.018027242,
-0.016620066,
0.08297003,
-0.02706634,
-0.015023872,
0.01835414,
0.03309716,
0.028929152,
-0.022870896,
-0.02315896,
-0.012377627,
0.048447836,
-0.045619972,
0.065583795,
0.03236358,
0.06425592,
-0.073378436,
...
Proces odczytu modelu oraz parametrów normalizacji przedstawiono na listingu 6.10. Wykorzystano w tym celu konstruktor klasy MnistDenseModel:
public MnistDenseModel(string? modelFilePath) : base(new SoftmaxCrossEntropyLoss(), null, modelFilePath)
{
}
gdzie parametr modelFilePath jest ścieżką do pliku JSON.
// Load test data
float[,] test = LoadCsv("..\\..\\..\\..\\..\\data\\MNIST\\mnist_test.csv");
(float[,] xTest, float[,] yTest) = Split(test);
// Load standardization stats
// Note: We have to use the same mean and stdDev as used during training.
var stats = File.ReadAllText($"{ModelName}.stats").Split(';');
float mean = float.Parse(stats[0]);
float stdDev = float.Parse(stats[1]);
xTest.AddInPlace(-mean);
xTest.DivideInPlace(stdDev);
// Load the model
MnistDenseModel model = new($"{ModelName}.json");
Listing 6.10. Odczyt modelu
6.3. Aproksymacja funkcji sinusoidalnej
Zobaczmy teraz w jaki sposób możemy użyć biblioteki NeuralNetworks do aproksymacji funkcji sinusoidalnej o amplitudzie rosnącej liniowo wraz z wartością bezwzględną z \(x\) (czyli funkcji \(y = |x| \cdot \sin(x)\)) w zakresie \([-2\pi, 2\pi]\). W tym celu zdefiniujemy prostą sieć neuronową z dwiema warstwami gęstymi, a następnie wytrenujemy ją na danych syntetycznych, wygenerowanych przez tę funkcję.
Note
Poniższy kod w pełnej wersji znajduje się na GitHub.
6.3.1. Architektura modelu
Poniżej przedstawiono strukturę omawianej sieci.
internal class SineFunctionModel(SeededRandom? random)
: BaseModel<float[,], float[,]>(new MeanSquaredErrorLoss(), random)
{
protected override LayerListBuilder<float[,], float[,]> CreateLayerListBuilder()
{
GlorotInitializer initializer = new(Random);
return AddLayer(new DenseLayer(32, new Tanh2D(), initializer))
.AddLayer(new DenseLayer(32, new Tanh2D(), initializer))
.AddLayer(new DenseLayer(1, new Linear(), initializer));
}
}
Listing 6.11. Definicja modelu do aproksymacji funkcji sinusoidalnej - dwie warstwy gęste z 32 neuronami i funkcją aktywacji Tanh oraz warstwa wyjściowa z funkcją liniową
6.3.2. Dane źródłowe
Dane treningowe i testowe są generowane z funkcji \(y = |x| \cdot \sin(x)\) dla wartości \(x \in [-2\pi, 2\pi]\). Wykorzystano do tego zadania następujący kod:
// Create data set
int sampleCount = 1_000;
List<(float x, float y)> data = [];
for (int i = 0; i < sampleCount; i++)
{
float x = -2 * MathF.PI + 4 * MathF.PI * i / sampleCount;
float y = MathF.Abs(x) * MathF.Sin(x);
data.Add((x, y));
}
// Shuffle
SeededRandom random = new(RandomSeed);
data = [.. data.OrderBy(_ => random.Next())];
// Split 80/20
int trainSize = (int)(0.8f * sampleCount);
int testSize = sampleCount - trainSize;
List<(float x, float y)> train = data[..trainSize];
List<(float x, float y)> test = data[trainSize..];
// Create data source (float[] xTrain, float[] yTrain, float[] xTest, float[] yTest)
float[,] xTrain = new float[trainSize, 1];
float[,] yTrain = new float[trainSize, 1];
for (int i = 0; i < trainSize; i++)
{
xTrain[i, 0] = train[i].x;
yTrain[i, 0] = train[i].y;
}
float[,] xTest = new float[testSize, 1];
float[,] yTest = new float[testSize, 1];
for (int i = 0; i < testSize; i++)
{
xTest[i, 0] = test[i].x;
yTest[i, 0] = test[i].y;
}
SimpleDataSource<float[,], float[,]> dataSource = new(xTrain, yTrain, xTest, yTest);
Listing 6.12. Generowanie danych treningowych i testowych do aproksymacji funkcji sinusoidalnej
Następnie dane te poddano standaryzacji (normalizacji do średniej 0 i odchylenia standardowego 1).
6.3.3. Trenowanie modelu
Trenowanie modelu odbywa się analogicznie do poprzednich przykładów:
SineFunctionModel model = new(random);
LearningRate learningRate = new ExponentialDecayLearningRate(0.01f, 0.005f);
Trainer<float[,], float[,]> trainer = new(
model,
new AdamOptimizer(learningRate),
random: random,
logger: Program.LoggerFactory.CreateLogger<SineFunction>()
);
trainer.Fit(
dataSource,
epochs: 1_000,
evalEveryEpochs: 100,
logEveryEpochs: 100,
batchSize: 250
);
Listing 6.13. Trenowanie modelu do aproksymacji funkcji sinusoidalnej
6.3.4. Rezultat trenowania
Po zakończeniu trenowania uzyskaliśmy wyniki przedstawione na poniższej ilustracji.
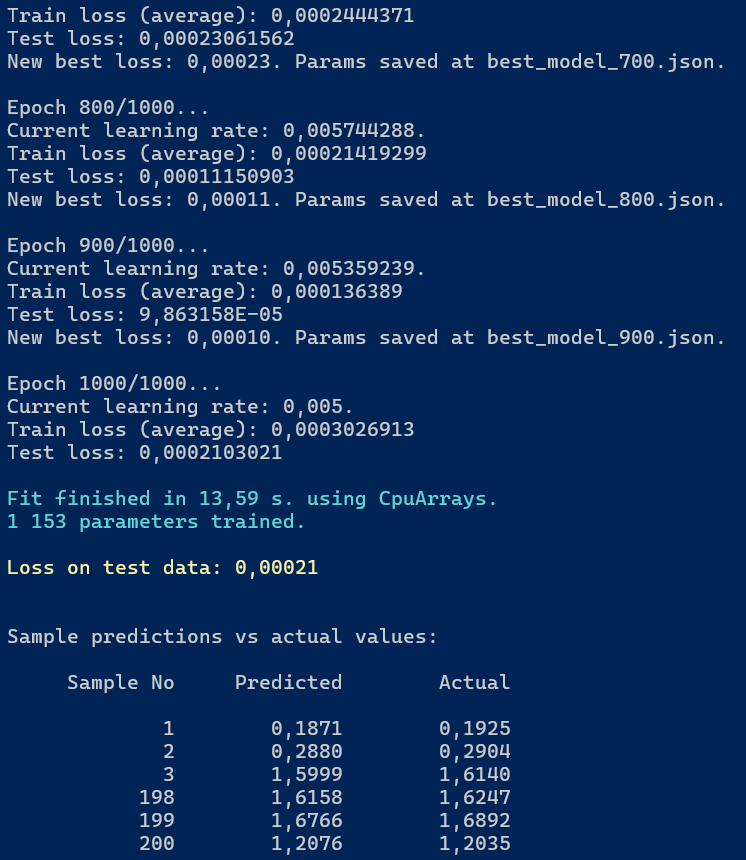
Rysunek 6.4. Rezultat trenowania modelu do aproksymacji funkcji sinusoidalnej
Otrzymano następujące wartości straty:
- MSE na zbiorze treningowym (średnia): 0,00031
- MSE na zbiorze testowym: 0,00029
6.3.4.1. Wizualizacja aproksymacji
Przyjrzyjmy się teraz graficznej ilustracji aproksymacji funkcji sinusoidalnej przez wytrenowany model.
Poniższy wykres przedstawia funkcję aproksymowaną \(y = |x| \cdot \sin(x)\) (linia niebieska) oraz jej aproksymację dokonaną przez model (linia czerwona) w zakresie \([-3\pi, 3\pi]\). Zakres ten jest szerszy niż zakres danych treningowych (o \(2\pi\)), ponieważ chcieliśmy zobaczyć, jak model radzi sobie z ekstrapolacją tej funkcji spoza zakresu danych treningowych.
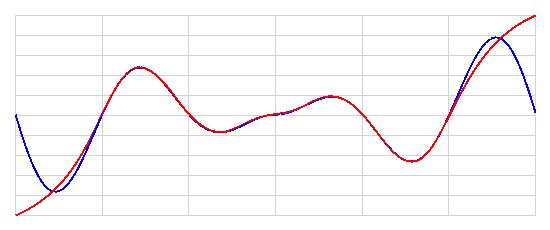
Rysunek 6.5. Aproksymacja funkcji sinusoidalnej przez wytrenowany model w zakresie \([-3\pi, 3\pi]\)
Jako ciekawostkę możemy również przedstawić wykres funkcji Sinus (\(y = \sin(x)\)) wraz z jej aproksymacją:
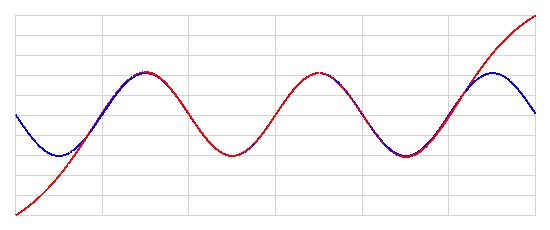
Rysunek 6.6. Aproksymacja funkcji Sinus w zakresie \([-3\pi, 3\pi]\) przez wytrenowany model
6.4. Podsumowanie
W tym rozdziale przedstawiliśmy praktyczne zastosowanie biblioteki NeuralNetworks do analizy danych Boston Housing i MNIST. Dodatkowo, pokazaliśmy, jak aproksymować funkcję sinusoidalną za pomocą sieci neuronowej.
W przypadku danych Boston Housing zbudowaliśmy prostą sieć neuronową z jedną warstwą gęstą, a dla danych MNIST stworzyliśmy model z trzema warstwami gęstymi. Omówiliśmy proces przygotowania danych, trenowania modeli oraz interpretacji wyników. Ponadto pokazaliśmy, jak zapisać i odczytać model z pliku, co jest przydatne dla wykorzystania wytrenowanego modelu w praktyce.
W kolejnych rozdziałach skupimy się na bardziej zaawansowanych architekturach sieci neuronowych, takich jak sieci konwolucyjne 1D i 2D, które są szczególnie skuteczne w zadaniach związanych z analizą obrazów, takich jak klasyfikacja danych MNIST oraz analizach związanych z danymi czasowymi (ECG200).
Created: 2025-12-19
Last modified: 2026-04-19
Title: 6. Użycie biblioteki NeuralNetworks
Tags: [C#] [Sieci neuronowe] [Biblioteka] [NeuralNetworks] [MNIST] [Warstwy gęste] [Dense Layers] [Fully Connected Layers] [Boston Housing]